Editor’s Note: This blog is a repost of original content from IOSG Ventures. IOSG Ventures is a community-friendly and research-driven early-stage venture firm. This blog post represents the independent views of the author, who has given permission for re-publication.
The programmable layer on FIL, the FVM, allows for trustless marketplaces to be built
This calls for a need for a marketplace that currently exists off-chain, i.e. FIL borrowing to be brought on-chain, where FIL token holders lease their FIL to Storage Providers (which some call “miners”) who borrow FIL from the pool(s)
FIL borrowing is essentially taking cash forward on the future block rewards accrued by the Storage Providers, and this makes FIL block rewards from data storage more capital-efficient
There are obvious trade-offs to be made between centralization-capital efficiency- and security in protocol design
The market size for borrowing FIL is reducing over time but the introduction of stablecoins, etc. Can unlock unique projects to be built on top of these protocols
The launch of a programmability layer on a seasoned blockchain generally comes with a lot of excitement. The launch of Stacks (STX) on the Bitcoin blockchain brought a new paradigm of thinking amongst the community built around it.
A very similar narrative happened with the launch of the FVM on Filecoin. The robust Filecoin community now has to see its vision through a completely different lens. A lot of open problems that the ecosystem had could now be addressed. Creating trustless marketplaces via programmability was a key piece of the puzzle.
Liquid staking on Filecoin was the first “Request-for-build” from the Filecoin ecosystem during the launch of FVM and was given high importance. To understand why this is, let us first understand how the economics of Filecoin work.
How Filecoin Incentives Work
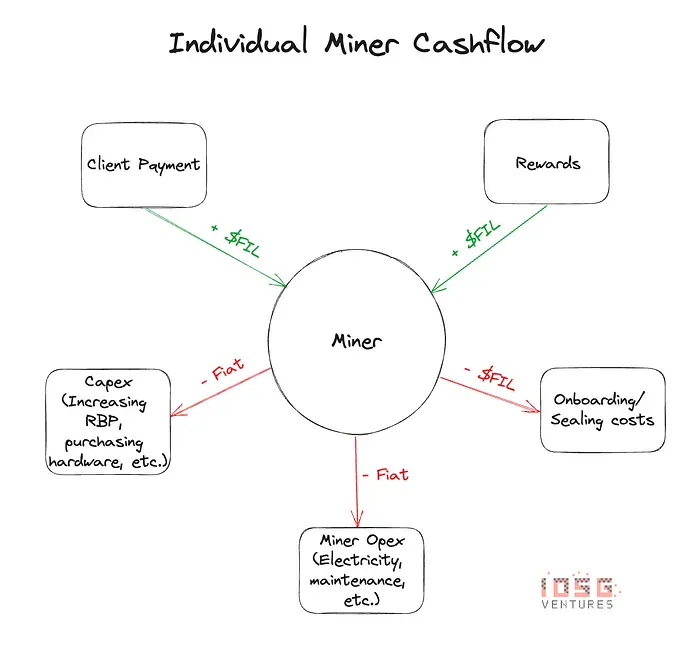
Unlike an Ethereum validator, there is no one-time staking in Filecoin. Every time a Storage Provider (SP) provides services, they need to put up a pledge amount in FIL. This pledge is required to seal the sectors and store the sealed sector in the SP. Such a structure ensures that the SP is going to store data for their clients for the period of the deal that they agree to, in exchange for rewards. Rewards are distributed via PoSt (Proof of Space-Time), where the SPs are rewarded for proving that they have the right client data stored.
SPs are selected via a leader selection mechanism called DRAND. DRAND chooses the leader with some initial requirements and also the % of raw byte power of the network controlled by the SPs.
SPs will have to keep ramping up raw byte power (RBP) to be chosen as the leader to “mine” a block and receive incentives. This helps the SP subsidize their storage costs.
Although there are many more factors that govern the supply rate of these incentives, the baseline is that for storage providers/miners, to maximize their bottom line will have to try to maximize RBP and onboard (and renew) more deals.
This creates a positive loop for the Filecoin network
Economics of a Storage Provider
When an SP receives block rewards, these rewards are not liquid. Only 25% of the rewards are liquid, and the remaining 75% of the block rewards vest linearly over 180 days (~ 6 months). This poses a problem for SPs. The rewards, which are supposed to be an SP’s operating income, are now delayed payments for as long as the SP onboards/renews deals.
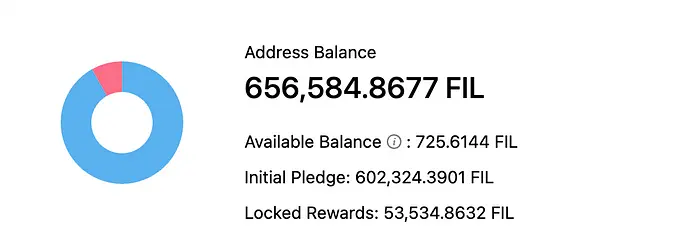
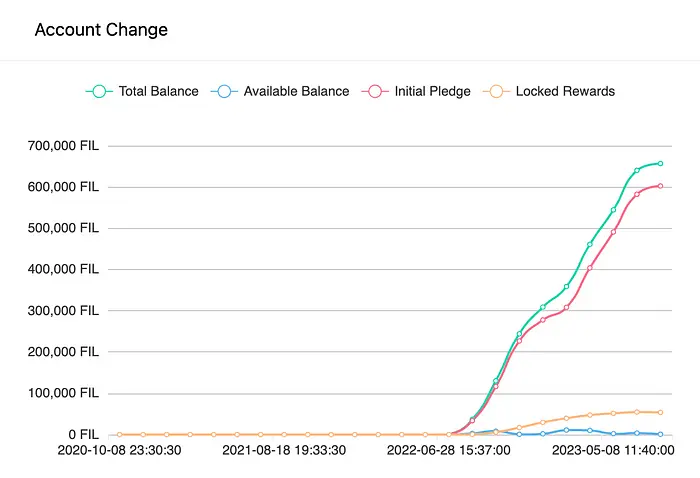
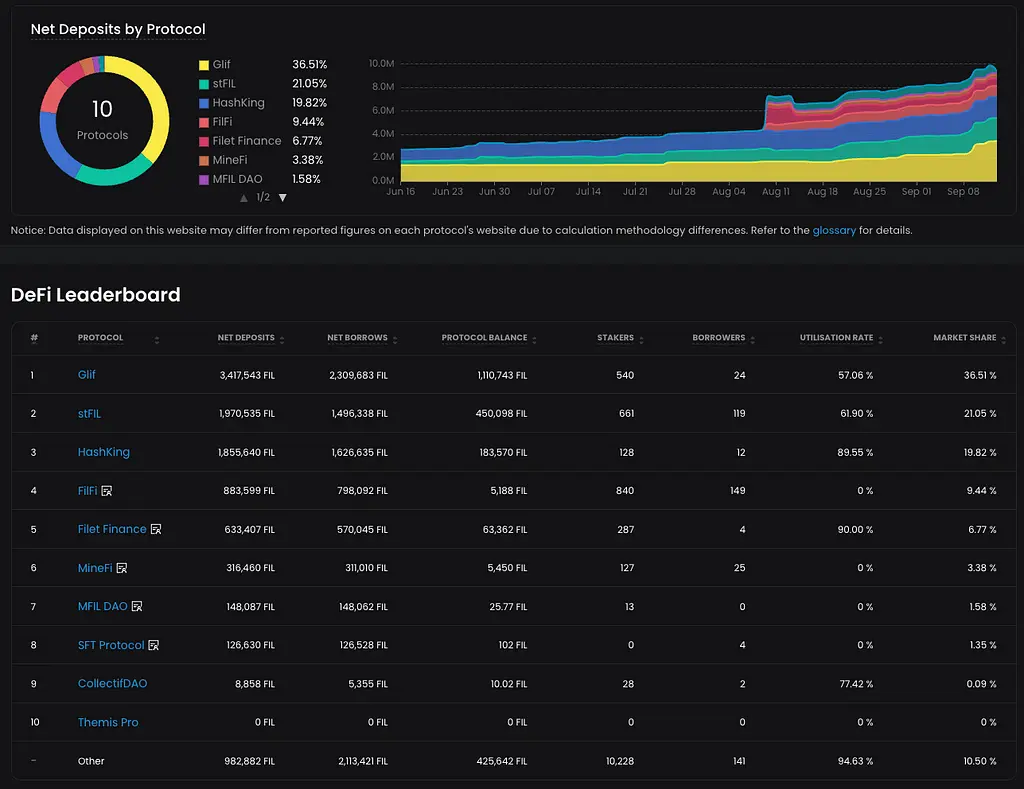
Let us look at the SP balance of the top miner in the network (as of 6th August 2023)
When you look at the graph, one can see that only about 1% of the rewards (or operating income) of the SP is actually liquid. If this SP now wants to either:
Pay for operating income
Upgrade hardware
Pay for maintenance
Or onboard/ renew deals
The SP will have to either borrow fiat currency or borrow FIL from third parties just to make up for these “delayed” payments.
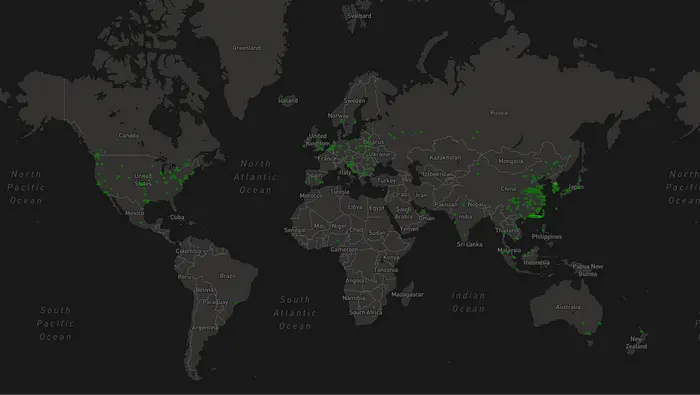
At the moment many storage providers (miners) in the network rely on CeFi lenders such as DARMA Capital, Coinlist, and a few others. As these are loan products, storage providers will have to go through KYC and a strict audit process to be able to borrow FIL. When we look at the map below, we can see a very high concentration of Filecoin SPs in Asia, and with centralized providers being mostly in the West, it is very hard for them to underwrite FIL loans to Asian miners with favorable terms, and most Asian miners/ SPs don’t have access to such providers.
This becomes a hindrance for new SPs to come in and participate in the system, and existing SPs can scale their business only as much as the total FIL pool size of these CeFi lenders
So why not just borrow fiat currency from a bank? With FIL being a volatile asset, it will pose additional capital management challenges for SPs who borrow.
To solve this problem, there needs to be a marketplace for FIL lenders (who could be holders of FIL) and FIL borrowers (SPs)
Filecoin Staking
With the launch of the FVM, this marketplace idea can come to fruition. FIL lenders/stakers can now put their FIL to work and SPs can borrow from this pool (either in a permissioned or permissionless manner) all governed by smart contracts.
There are many players in the ecosystem who are already building this and waiting to launch in the coming months.
More than calling such marketplaces staking protocols, it is a lot closer to a lending protocol by the nature of this business.
Some base features of such a FIL lending product would be:
Lenders deposit idle FIL and receive a “liquid staking” token
Borrowers (SPs) can borrow from the pool against collateral that exists in the SP actor (Essentially Initial Pledge + Locked Rewards)
Borrowers will make interest payments every week, or any specified time period, by signing over the “OwnerID” of the SP to a smart contract
Lenders receive the interest (minus protocol fees) as APY either via a rebase token or a value accrual token
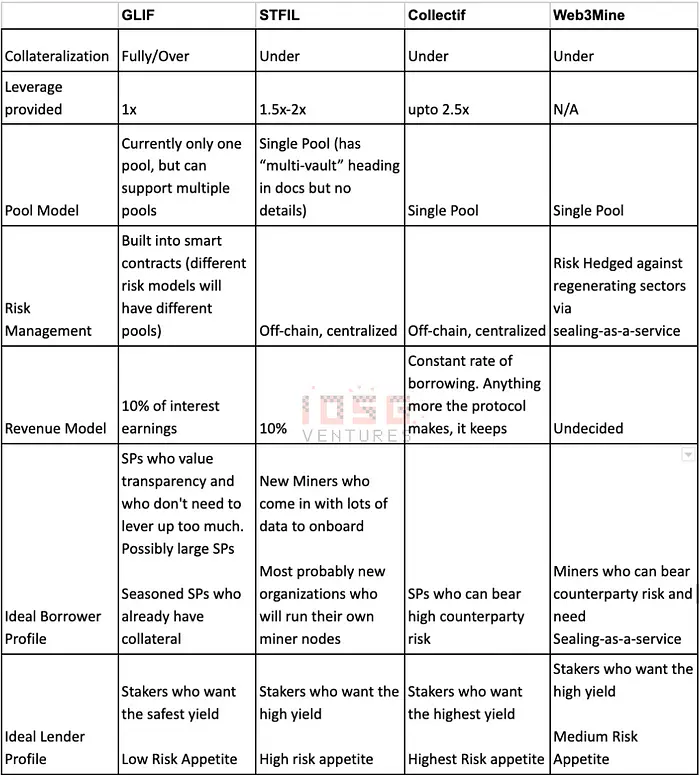
Different liquid staking protocols have different schools of thought when it comes to borrowing:
Over/ Fully collateralized vs. Undercollateralized
In Over-collateralized or fully collateralized models, the debt-to-equity ratio is always going to be less than or equal to 100%. This means that if my SP balance is say 1000 FIL, I can only borrow up to 1000 FIL (depending on the protocol rules as well). This can easily be coded into smart contracts and default risk is built in. This allows for greater transparency and also security to the stakers (lenders). Another advantage of such a model is that it allows for permissionless borrowing as well. This is where the product blocks more like Aave/ Compound rather than a Lido or RocketPool.
In an uncollateralized model, the lenders are bearing risk while the risk is being managed by the protocol. In such a model, risk modeling is complex math that cannot be baked into smart contracts, and needs to be off-chain which sacrifices transparency. But, since there is leverage involved, it makes the system a lot more capital-efficient for the borrower. The more permissionless a leveraged system will get, the more risk the lenders bear and this would call for a very robust and dynamic risk management model that is run by the protocol developers
The trade-offs being made are:
Capital efficiency vs. staker risk
Capital efficiency vs. transparency
Lender risk vs. borrower entry to the system
Single Pool vs Multi-Pool
Protocols can also opt to build a multi-pool model where lenders can choose to stake FIL in different pools with different risk parameters. This allows for risk to be managed on-chain, but liquidity will be fragmented. In a single-pool model, risk will have to be maintained off-chain. Overall the trade-offs will still remain the same as the ones mentioned above.
Trade-off: Liquidity fragmentation vs Risk management transparency
Risks
In an overcollateralized model, even if the miner gets slashed multiple times, as soon as the Debt-to-equity ratio hits 100% the miner will get liquidated and the stakers will be comparatively safe
In an undercollateralized model, the borrowers can be penalized for failing to prove sectors. There are many more faults in failing to prove data storage rather faults in the consensus itself. This is more common in Filecoin than in other general-purpose blockchains because there is an actual commodity that is being stored from an off-chain entity. This will affect the collateral value and lever the borrower more. Liquidation thresholds will have to be set very carefully in such a model.
What about Ethereum Staking/Lending protocols entering the market?
In the Filecoin ecosystem, unlike the Ethereum ecosystem, the nodes (Miners/Validators/SPs) are responsible for much more than general uptime. They are supposed to market themselves to be chosen as SPs, and regularly upgrade their hardware to support more storage, seal, store, maintain, and retrieve data. Filecoin storage and reward mining for SPs is a full-time job.
Unlike an Ethereum validator, there is no one-time staking in Filecoin. Every time an SP provides storage to a client, they need to put up a pledge. This pledge is required to seal the sectors and store the sealed sector in the SP. Storage provision on Filecoin is a very capital-intensive process and this discourages many new SPs from participating in the network and existing SPs from staying and contributing to the network.
Since the participants on the borrow side are SPs only it is also going to be intensive for newcomers in the Filecoin ecosystem to bootstrap borrower trust.
The mechanics of Filecoin alone don’t allow Ethereum staking or even lending protocols to deploy easily on the FVM.
Economics of the Protocol
Is there enough FIL in the market to supply for lending?
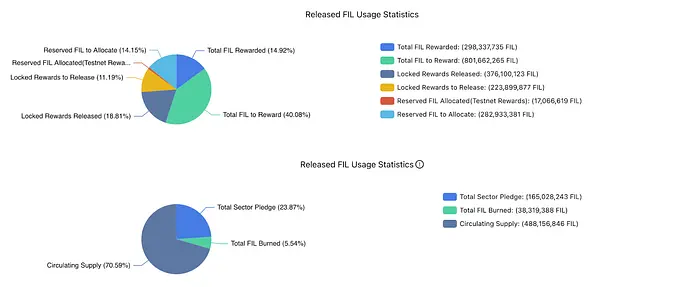
As of August 6th, 2023, there are about 264.2 million FIL circulating that are not committed as sector pledges or rewards that are to be released. This can be counted as the total amount of FIL that can be staked by the lenders into the pool
While FIL borrowing is essential to SPs, what are they actually borrowing? They are taking a forward payment on their locked-up rewards in an overcollateralized model, and in the undercollateralized model, they are taking a forward payment on future rewards.
Looking at the graphs above, we can see that the total locked rewards are about 223M FIL, and the supply can match the demand. The demand-to-supply ratio is almost 84%. This shows even power dynamics on either side, and either side cannot squeeze the other on interest rates/ APY.
What does the future look like?
Estimating the market for future demand of FIL for borrowing is essentially the amount of FIL that will be released in the future as rewards.
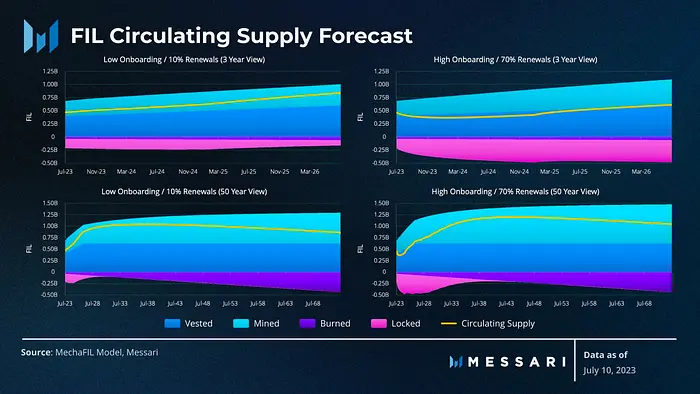
The good folks at Messari ran a simulation of FIL circulating supply with a 3-year and a 50-year forecast using different cases.
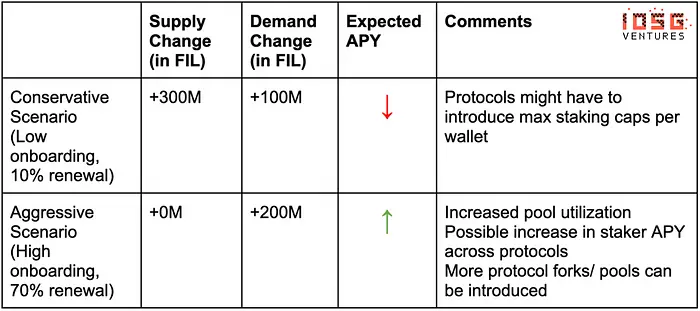
According to the top left graph, considering a conservative scenario where there is low onboarding of data and only 10% of the total deals are renewed, the new reward emissions over 3 years are close to around 100M FIL and in an aggressive scenario where there is a high amount of data onboarding and 70% of existing deals renewed, the extra rewards come to about 200M FIL
So one can expect a market size of somewhere between 100M — 200M FIL over the next 3 years. At the current price of FIL (Aug 6th), which is $4.16, there could be a borrowing TAM of about $400M — $800M. This could be counted as the TAM of the product’s borrow side.
On the supply side, in the conservative estimate, there can be about 300M FIL that will be emitted, and in a more aggressive scenario, the circulating supply is simulated to be around the same as it is today. Why? It is because if more deals are being onboarded and renewed, there will be a lot more FIL locked-in sector pledges.
In the more aggressive scenario, the demand is going to outweigh the supply and the interest charged can be higher in this competitive market.
Where I think this can go
Amongst the different designs, there need not be a winner-takes-all type of model. Intuitively, the long-term winner (by TVL) is generally the protocol that is built most safely. Very much like Lido in the Ethereum ecosystem. I for one am biased towards safer structures more than optimizing for 2–3% more yield, and I think FIL whales would also prioritize capital safety over a slightly higher yield.
This is after considering the amount of penalties miners pay for not being able to prove space-time.
From the borrower (SP) end, the SP could borrow from different protocols for different purposes. If the SP already has a lot of collateral and doesn’t need to lever up to pay for opex, then the safer, overcollateralized model will work better, since it is safer. Whereas if I am a newer SP with a lot of sectors to be pledged I would borrow with leverage from an undercollateralized pool.
After studying the above models, we can see:
Staking in Filecoin is important to bridge the supply and demand for FIL in the ecosystem. The FVM has recently been released allowing for a lending marketplace to exist. Although the problem is real, the FVM release was probably too late for most FIL staking/lending protocols as the pie (mining rewards) is decreasing over time making it a niche market.
However, a few fascinating use cases can emerge on top of these staking protocols. With the introduction of stablecoins, the rewards can be taken as cash forwards. Something similar to what Alkimiya is building on Ethereum. This can result in the injection of new capital into the Filecoin ecosystem and also increase the TVL in these protocols.
Ethereum’s and Filecoin’s tech is different, their miners are different, their developers are different, their apps are different, and hence their communities. And for staking in particular, with every miner being “non-fungible” bootstrapping the demand side becomes a BD exercise and the success of it is directly proportional to the protocol’s reputation in the community.
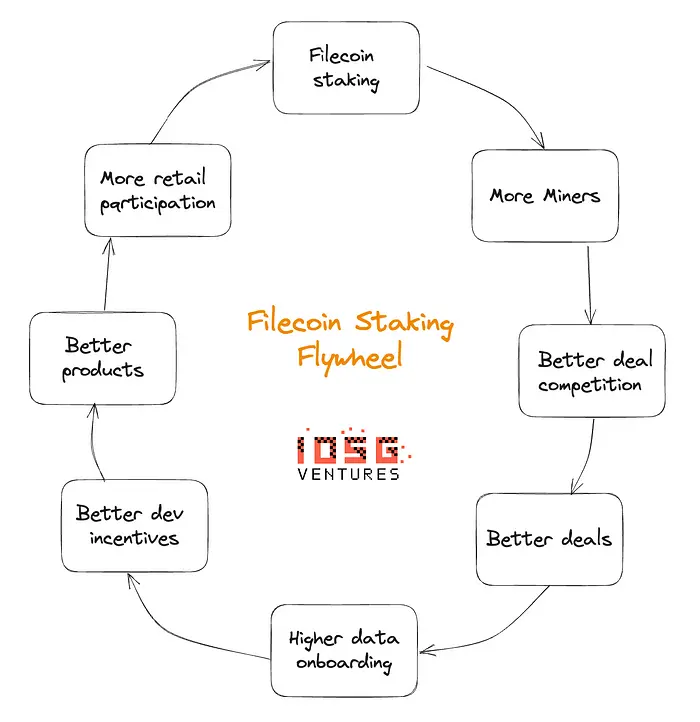
Filecoin staking is a critical solution that needs to be built to get more SPs in the system, for retail to put their capital to work, create greater economic incentives as an ecosystem to attract more developers, and build useful products to build a positive flywheel. To know more beyond staking in the Filecoin ecosystem and the criticality of the FVM you can read this previous piece we published.
There are many more open problems to be solved in the Filecoin ecosystem, but we are positive that the Filecoin Ecosystem is working in the right direction to achieve its vision of storing humanity’s data in an efficient system.
Editor’s Note: This article draws heavily from David Aronchick’s presentation at the Filecoin Unleashed Paris 2023. David is the CEO of Expanso and former head of Compute-over-data at Protocol Labs which is responsible for the launch of the Bacalhau project. This blog post represents the independent view of the creator of the original content, who has given permission for this re-publication.
The world will store more than 175 zettabytes of data by 2025, according to IDC. That’s a lot of data, precisely 175 trillion 1GB USB sticks. Most of this data will be generated between 2020 and 2025, with an estimated compound annual growth of 61%.
The rapidly growing data sphere broadly poses two major challenges today:
Moving data is slow and expensive. If you attempted to download 175 zettabytes at current bandwidth, it would take you roughly 1.8 billion years.
Compliance is hard. There are hundreds of data-related governances worldwide which makes compliance across jurisdictions an impossible task.
The combined result of poor network growth and regulatory constraints is that nearly 68% of enterprise data is unused. That’s precisely why moving compute resources to where the data is stored (broadly referred to as compute-over-data) rather than moving data to the place of computation becomes all the more important, something which compute-over-data (CoD) platforms like Bacalhau are working on.
In the upcoming sections, we will briefly cover:
How organizations are currently handling data today
Propose alternative solutions based on compute-over-data
There are three main ways in which organizations are navigating the challenges of data processing today — none of which are ideal.
Using Centralized Systems
The most common approach is to lean on centralized systems for large-scale data processing. We often see enterprises use a combination of compute frameworks — Adobe Spark, Hadoop, Databricks, Kubernetes, Kafka, Ray, and more — forming a network of clustered systems that are attached to a centralized API server. However, such systems fall short of effectively addressing network irregularities and other regulatory concerns around data mobility.
This is partly responsible for companies coughing up billions of dollars in governance fines and penalties for data breaches.
Building It Themselves
An alternative approach is for developers to build custom orchestration systems that possess the awareness and robustness the organizations need. This is a novel approach but such systems are often exposed to risks of failure by an over-reliance on a few individuals to maintain and run the system.
Doing Nothing
Surprisingly, more often than not, organizations do nothing with their data. A single city, for example, may collect several petabytes of data from CCTV recordings a day and only view them on local machines. The city does not archive or process these recordings because of the enormous costs involved.
Building Truly Decentralized Compute
There are 2 main solutions to the data processing pain points.
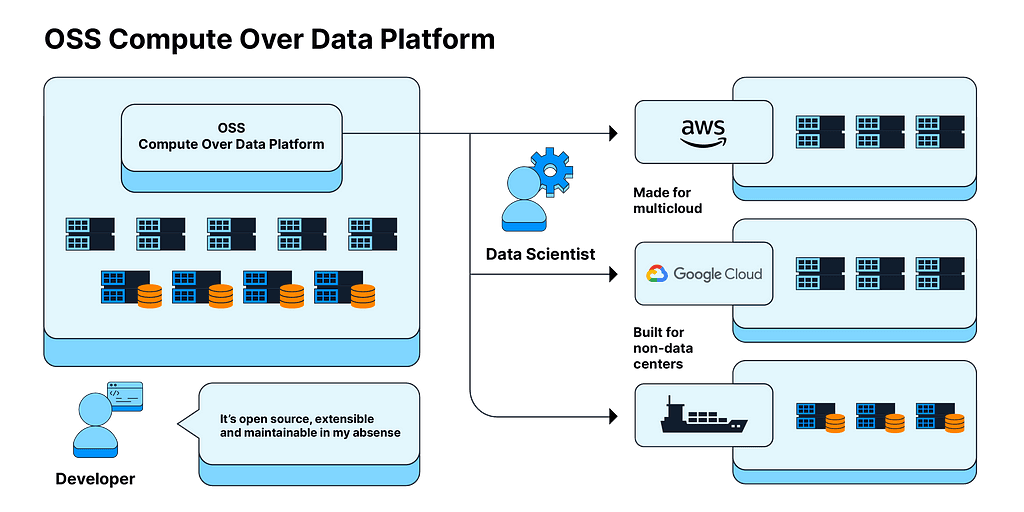
Solution 1: Build on top of open-source compute-over-data platforms.
Solution 1: Open Source Compute Over Data Platforms
Instead of using a custom orchestration system as specified earlier, developers can use an open-source decentralized data platform for computation. Because it is open source and extensible, companies can build just the components they need. This setup caters to multi-cloud, multi-compute, non-data-center scenarios with the ability to navigate complex regulatory landscapes. Importantly, access to open-source communities makes the system less vulnerable to breakdowns as maintenance is no longer dependent on one or a few developers.
Solution 2: Build on top of decentralized data protocols.
With the help of advanced computational projects like Bacalhau and Lilypad, developers can go a step further and build systems not just on top of open-source data platforms as mentioned in Solution 1, but on truly decentralized data protocols like the Filecoin network.
Solution 2: Decentralized Compute Over Data Protocols
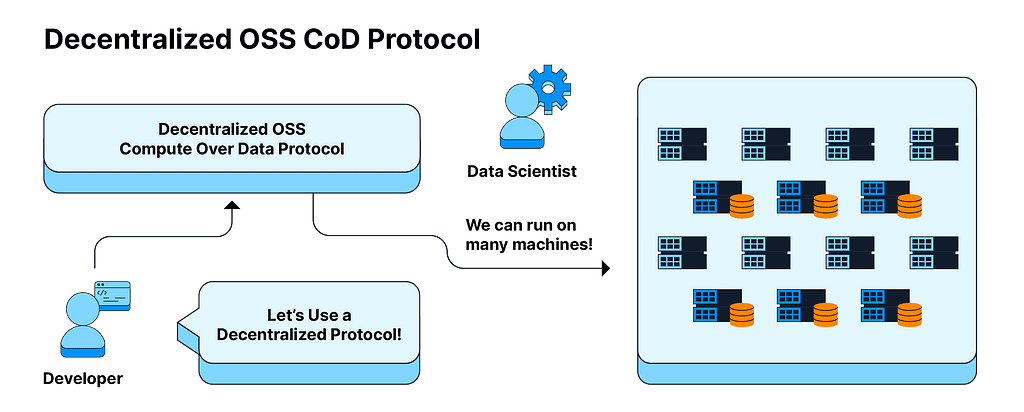
What this means is that organizations can leverage decentralized protocols that understand how to orchestrate and describe user problems in a much more granular way and thereby unlock a universe of compute right next to where data is generated and stored. This switchover from data centers to decentralized protocols can be carried out ideally with very few changes to the data scientists’ experience.
Decentralization is About Maximizing Choices
By deploying on decentralized protocols like the Filecoin network, the vision is that clients can access hundreds (or thousands) of machines spread across geographies on the same network, following the same protocol rules as the rest. This essentially unlocks a sea of options for data scientists as they can request the network to:
Select a dataset from anywhere in the world
Comply with any governance structures, be it HIPAA, GDPR, or FISMA.
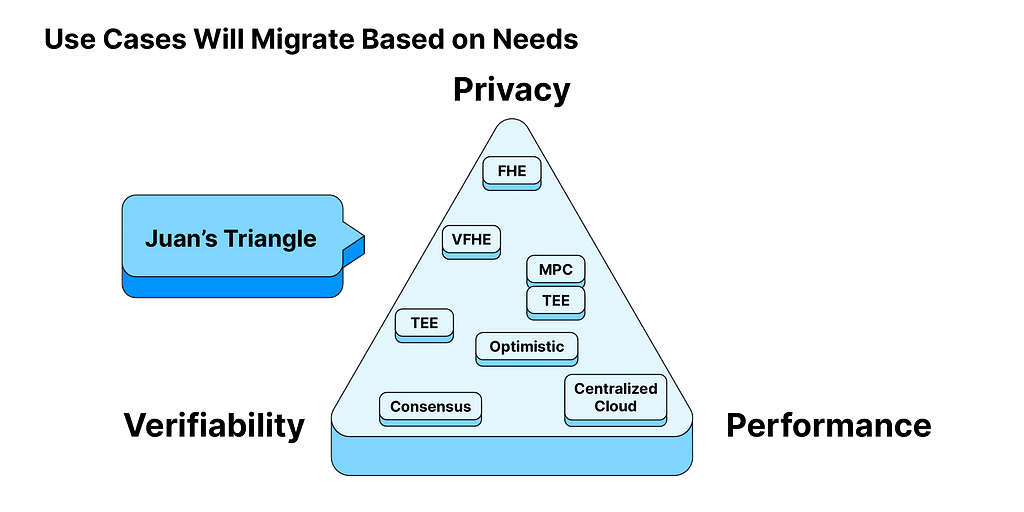
The concept of maximizing choices brings us to what’s called “Juan’s triangle,” a term coined after Protocol Labs’ founder Juan Benet for his explanation of why different use cases will have (in the future) different decentralized compute networks backing them.
Juan’s triangle explains that compute networks often have to trade off between 3 things: privacy, verifiability, and performance. The traditional one-size-fits-all approach for every use case is hard to apply. Rather, the modular nature of decentralized protocols enables different decentralized networks (or sub-networks) that fulfill different user requirements — be it privacy, verifiability, or performance. Eventually, it is up to us to optimize for what we think is important. Many service providers across the spectrum (shown in boxes within the triangle) fill these gaps and make decentralized compute a reality.
In summary, data processing is a complex problem that begs out-of-the-box solutions. Utilizing open-source compute-over-data platforms as an alternative to traditional centralized systems is a good first step. Ultimately, deploying on decentralized protocols like the Filecoin network unlocks a universe of compute with the freedom to plug and play computational resources based on individual user requirements, something that is crucial in the age of Big Data and AI.
Follow the CoD working group for all the latest updates on decentralized compute platforms. To learn more about recent developments in the Filecoin ecosystem, tune into our blog and follow us on social media at TL;DR, Bacalhau, Lilypad, Expanso, and COD WG.
Unlike proof-of-stake cryptocurrency protocols that directly provide rewards for locking staked tokens, “staking” FIL is much more akin to a lease.
You may have heard of services or applications that enable “Filecoin staking.” However, “staking” on the Filecoin network is different from proof-of-stake cryptocurrency protocols like Ethereum. Filecoin “staking” allows storage providers (SPs) to borrow FIL which they use as collateral to provide storage on the Filecoin network.
Unlike proof-of-stake cryptocurrency protocols that directly provide rewards for locking staked tokens, “staking” FIL is much more akin to a lease. SPs borrow FIL to use as collateral and may pay a fee. Applications facilitating this may also take a fee.
You can think of a FIL lease to a storage provider like a car being leased to an Uber driver who makes money providing rides through the Uber platform. During the lease term, the car owner receives lease payments from the Uber driver; when the lease is over, the car is returned to the owner.
Why do storage providers need FIL collateral?
Filecoin storage providers (SPs) contribute data storage capacity to the Filecoin network.
In order to ensure that files are stored reliably over time, SPs are required to post FIL as collateral. If an SP fails to meet their responsibilities (perhaps they go offline or stop storing certain files) their collateral is slashed, meaning that they lose a portion of the FIL they posted as collateral.
A storage provider can buy or earn FIL to provide the collateral they need to run their data storage business, or they might borrow/lease FIL from existing token holders.
Centralized vs decentralized applications
Third-party centralized programs enable storage providers to borrow FIL to use as collateral. In the centralized model, token holders transfer custody of their FIL to centralized intermediaries for set periods of time. These intermediaries allow SPs to borrow FIL, and distribute fees collected to token holders.
This model requires that token holders trust the centralized intermediary with custody of their FIL. Some centralized programs rely on multi-sig transactions. Multi-sig is short for ‘multi-signature’, which means a transaction has two, or more, signatures before it is executed. However, multi-sigs still rely on human intervention.
Using any third-party application carries risks, and it is critical to thoroughly research any application to understand all these risks. Some areas to consider are:
Audits: Has a third-party audited the code and are the results published publicly?
Open Source: Is the code available to inspect publicly?
Bug Bounty: Does the program provide a bug bounty to incentivize anyone to report/fix possible vulnerabilities?
Trustless: Can you use the application without relying on an intermediary; is there a single point of failure?
Disclaimer: This information is for informational purposes only and does not constitute investment, financial, legal, or other advice. This information is not an endorsement, offer, or recommendation to use any particular service, product, or application.
This blog post is contributed to Filecoin TL;DR by a guest writer. Catrina is an Investment Partner at Portal Ventures.
Until recently, startups led the way in technological innovation due to their speed, agility, entrepreneurial culture, and freedom from organizational inertia. However, this is no longer the case in the rapidly growing era of AI. So far, big tech incumbents like Microsoft-owned OpenAI, Nvidia, Google, and even Meta have dominated breakthrough AI products.
What happened? Why are the “Goliaths” winning over the “Davids” this time around? Startups can write great code, but they are often too hindered to compete with big tech incumbents due to several challenges:
Compute costs remain prohibitively high
AI has a reverse salient problem: a lack of necessary guardrails impedes innovation due to fear and uncertainty around societal ramifications
AI is a black box
The data “moat” of scaled players (big tech) creates a barrier to entry for emerging competitors
So, what does this have to do with blockchain technology, and where does it intersect with AI? While not a silver bullet, DePIN (Decentralized Physical Infrastructure Networks) in Web3 unlocks new possibilities for solving the aforementioned challenges. In this blog post, I will explain how AI can be enhanced with the technologies behind DePIN across four dimensions:
Reduction of infrastructure costs
Verification of creatorship and humanity
Infusion of Democracy & Transparency in AI
Installation of incentives for data contribution
In the context of this article,
“web3” is defined as the next generation of the internet where blockchain technology is an integral part, along with other existing technologies
“blockchain” refers to the decentralized and distributed ledger technology
“crypto” refers to the use of tokens as a mechanism for incentivizing and decentralizing
Reduction of infra cost (compute and storage)
Every wave of technological innovation has been unleashed by something costly becoming cheap enough to waste
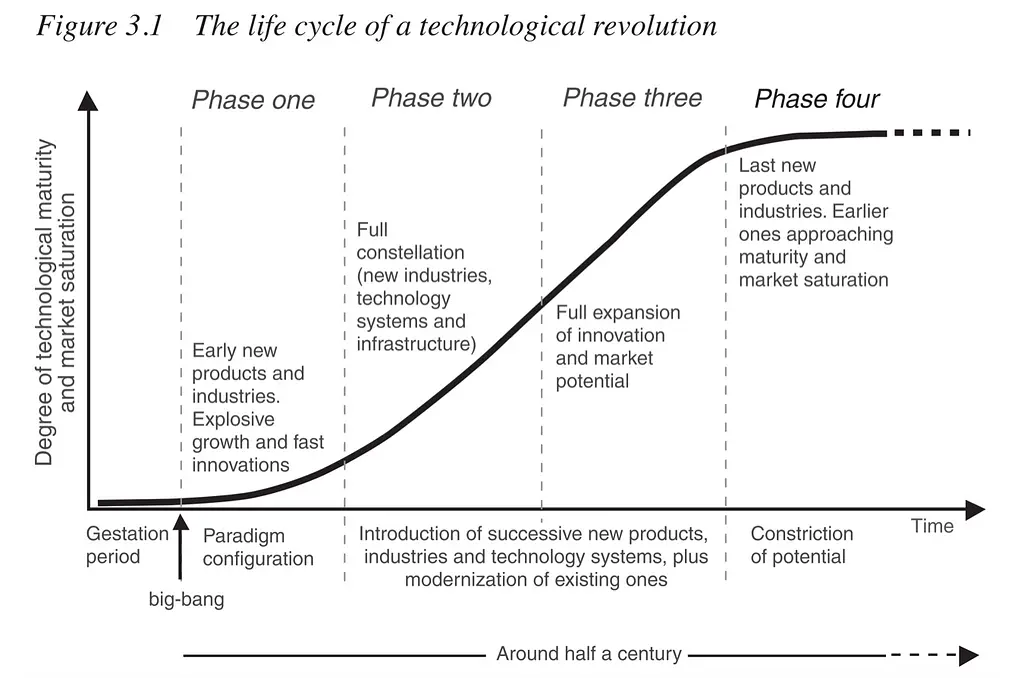
The importance of infra affordability (in AI’s case, the hardware costs to compute, deliver, and store data) is highlighted by Carlota Perez’s Technological Revolution framework, which proposed that every technological breakthrough comes with two phases:
The Installation stage is characterized by heavy VC investments, infrastructure setup, and a “push” go-to-market (GTM) approach, as customers are unclear on the value proposition of the new technology.
The Deployment stage is characterized by a proliferation of infrastructure supply that lowers the barrier for new entrants and a “pull” GTM approach, implying a strong product-market fit from customers’ hunger for more yet-to-be-built products.
With definitive evidence of ChatGPT’s product-market fit and massive customer demand, one might think that AI has entered its deployment phase. However, there is still one piece missingstill: an excess supply of infrastructure that makes it cheap enough for price-sensitive startups to build on and experiment with.
Problem
The current market dynamic in the physical infrastructure space is largely a vertically integrated oligopoly, with companies such as AWS, GCP, Azure, Nvidia, Cloudflare, and Akamai enjoying high margins. For example, AWS has an estimated 61% gross margin on commoditized computing hardware.
Compute costs are prohibitively high for new entrants in AI, especially in LLM.
Version two of Bloom will likely cost $10M to train & retrain
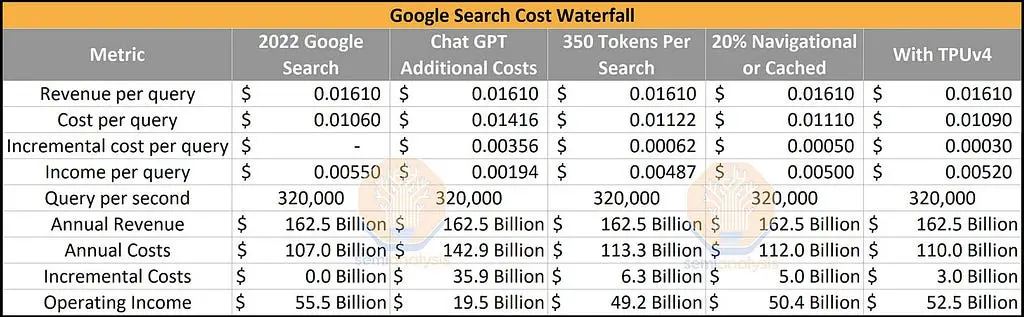
If ChatGPT were deployed into Google Search, it would result in $36B reduction in operating income for Google, a massive transfer of profitability from the software platform (Google) to the hardware provider (Nvidia)
DePIN networks such as Filecoin (the pioneer of DePIN since 2014 focused on amassing internet-scale hardware for decentralized data storage), Bacalhau, Gensyn.ai, Render Network, and ExaBits (the coordination layers to match the demand for CPU/GPU with supply) can deliver 75% — 90%+ cost savings in infra costs via below three levers
1. Pushing up the supply curveto create a more competitive marketplace
DePIN democratizes access for hardware suppliers to become service providers. It introduces competition to these incumbents by creating a marketplace for anyone to join the network as a “miner,” contributing their CPU/GPU or storage power in exchange for financial rewards.
While companies like AWS undoubtedly enjoy a 17-year head start in UI, operational excellence, and vertical integration, DePIN unlocks a new customer segment that was previously out-priced by centralized providers. Similar to how eBay does not compete directly with Bloomingdale but rather introduces more affordable alternatives to meet similar demand, DePIN networks do not replace centralized providers but rather aim to serve a more price-sensitive segment of users.
2. Balancing the economy of these markets with crypto-economic design
DePIN creates a subsidizing mechanism to bootstrap hardware providers’ participation in the network, thus lowering the costs to end users. To understand how let’s first compare the costs & revenue of storage providers in web2 vs. web3 using AWS and Filecoin.
Lower fees for clients: DePIN networks create competitive marketplaces that introduce Bertrand-style competition resulting in lower fees for clients. In contrast, AWS EC2 needs a mid-50% margin and 31% overall margin to sustain operations, plus
Token incentives/block rewards are emitted from DePIN networks as a new revenue source. In the context of Filecoin, hosting more real data translates to earning more block rewards (tokens) for storage providers. Consequently, storage providers are motivated to attract more clients and win more deals to maximize revenue. The token structures of several emerging compute DePIN networks are still under wraps, but will likely follow a similar pattern. Examples of such networks include:
Bacalhau: a coordination layer to bring computing to where data is stored without moving massive amounts of data
exaBITS: a decentralized computing network for AI and computationally intensive applications
Gensyn.ai: a compute protocol for deep learning models
3. Reducing overhead costs
Benefits of DePIN networks like Bacalhau and exaBITS, and IPFS/content-addressed storage include:
Creating usability from latent data: there is a significant amount of untapped data due to the high bandwidth costs of transferring large datasets. For instance, sports stadiums generate vast amounts of event data that is currently unused. DePIN projects unlock the usability of such latent data by processing data on-site and only transmitting meaningful output.
Reducing OPEX costs such as data input, transport, and import/export by ingesting data locally.
Minimizing manual processes to share sensitive data: for example, if hospitals A and B need to combine respective sensitive patient data for analysis, they can use Bacalhau to coordinate GPU power to directly process sensitive data on-premise instead of going through the cumbersome administrative process to handle PII (Personal Identifiable Information) exchange with counterparties.
Removing the need to recompute foundational datasets: IPFS/content-addressed storage has built-in properties that deduplicate, trace lineage, and verify data. Here’s a further read on the functional and cost efficiencies brought about by IPFS.
Summary by AI: AI needs DePIN for affordable infrastructure, which is currently dominated by vertically integrated oligopolies. DePIN networks like Filecoin, Bacalhau, Render Network, and ExaBits can deliver cost savings of 75%-90%+ by democratizing access to hardware suppliers and introducing competition, balancing the economy of markets with cryptoeconomic design, and reducing overhead costs.
Verification of Creatorship & Humanity
Problem
According to a recent poll, 50% of A.I. scientists agree that there is at least a 10% chance of A.I. leading to the destruction of the human race.
This is a sobering thought. A.I. has already caused societal chaos for which we currently lack regulatory or technological guardrails — the so-called “reverse salient.”
To get a taste of what this means, check out this Twitter clip featuring podcaster Joe Rogan debating the movie Ratatouille with conservative commentator Ben Shapiro in an AI-generated video.
Unfortunately, the societal ramifications of AI go much deeper than just fake podcast debates & images:
The 2024 presidential election cycle will be among the first where a deep fake AI-generated political campaign becomes indistinguishable from the real one
The voice clone of Biden criticizing transgender women
A group of artists filed a class-action lawsuit against Midjourney and Stability AI for unauthorized use of artists’ work to train AI imagery that infringed on those artists’ trademarks & threatened their livelihood
A deepfake AI-generated soundtrack, “Heart on My Sleeve” featuring The Weeknd and Drake, went viral before being taken down by the streaming service. Such controversy around copyright violation is a harbinger of the complications that can arise when a new technology enters the mainstream consciousness before the necessary rules are in place. In other words, it is a Reverse Salient problem.
What if we can do better in web3 by putting some guardrails on AI?
Solution
Proof of Humanity and Creatorship with cryptographic proof of origination on-chain
This is where we can actually use Blockchain for its technology — as a distributed ledger of immutable records that contain tamper-proof history on-chain. This makes it possible to verify the authenticity of digital content by checking its cryptographic proof.
Proof of Creatorship & Humanity with Digital Signature
To prevent deep fakes, cryptographic proof can be generated using a digital signature that is unique to the original creator of the content. This signature can be created using a private key, which is only known to the creator, and can be verified using a public key that is available to everyone. By attaching this signature to the content, it becomes possible to prove that the content was created by the original creator — whether they are human or AI — and authorized/unauthorized changes to this content.
Proof of Authenticity with IPFS & Merkle Tree
IPFS is a decentralized protocol that uses content addressing and Merkle trees to reference large datasets. To prove changes to a file’s content, a Merkle proof is generated, which is a list of hashes that shows a specific data chunk in the Merkle tree. With every change, a new hash is generated and updated in the Merkle tree, providing proof of file modification.
A pushback against such a cryptographic solution may be incentive alignment: after all, catching a deep fake generator doesn’t generate as much financial gain as it reduces the negative societal externality. The responsibility will likely fall on major media distribution platforms like Twitter, Meta, Google, etc. to flag, which they are already doing. So why do we need Blockchain for this?
The answer is that these cryptographic signatures and proof of authenticity are much more effective, verifiable, and deterministic. Today, the process to detect deep fakes is largely through machine learning algorithms (such as the “Deepfake Detection Challenge”of Meta, “Asymmetric Numeral Systems” (ANS) of Google, and c2pa) to recognize patterns and anomalies in visual content, which is not only inaccurate at times but also falling behind the increasingly sophisticated deep fakes. Often, human reviewer intervention is required to assess authenticity, which is not only inefficient but also costly.
Imagine a world where each piece of content has its cryptographic signature so that everyone will be able to verifiably prove the origin of creation and flag manipulation or falsification — a brave new one.
Summary by AI: AI poses a significant threat to society, with deep fakes and unauthorized use of content being major concerns. Web3 technologies, such as Proof of Creatorship with Digital Signature and Proof of Authenticity with IPFS and Merkle Tree, can provide guardrails for AI by verifying the authenticity of digital content and preventing unauthorized changes.
Infusion of Democracy in AI
Problem
Today, AI is a black box comprised of proprietary data + proprietary algorithms. Such closed-door nature of Big Tech’s LLM precludes the possibility of what I call an “AI Democracy,” where every developer or even user should be able to contribute both algorithms and data to an LLM model, and in term receive a fraction of the future profits from the model (as discussed here).
AI Democracy = visibility(the ability to see the data & algorithm input into the model)
contribution(the ability to contribute data or algorithm to the model).
Solution
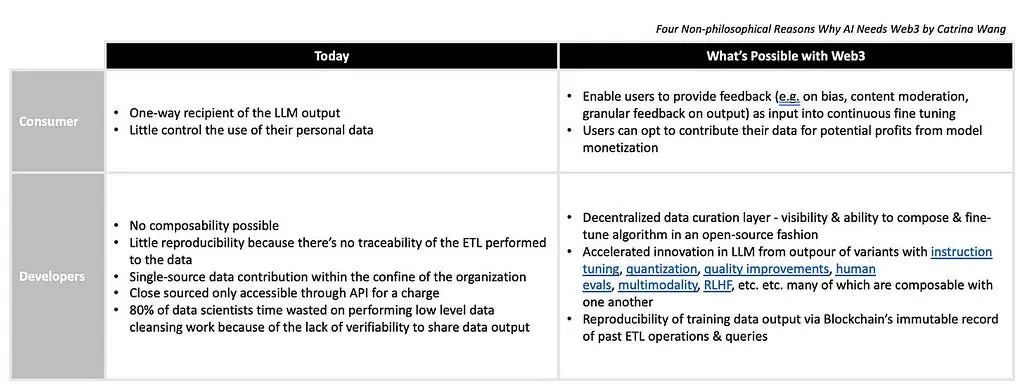
AI Democracy aims to make generative AI models accessible for, relevant to, and owned by everyone. The below table is a comparison illustrating what is possible today vs. What will be possible, enabled by blockchain technology in Web3.
Today:
For consumers:
One-way recipient of the LLM output
Little control over the use of their personal data
For developers:
Little composability possible
Little reproducibility because there’s no traceability of the ETL performed on the data
Single-source data contribution within the confine of the owner organization
Close sourced only accessible through API for a charge
80% of data scientists’ time is wasted on performing low-level data cleansing work because of the lack of verifiability to share data output
What blockchain will enable
For consumers:
Users can provide feedback (e.g. on bias, content moderation, granular feedback on output) as input into continuous fine-tuning
Users can opt to contribute their data for potential profits from model monetization
For developers:
Decentralized data curation layer: crowdsource tedious & time-consuming data preparation processes such as data labeling
Visibility & ability to compose & fine-tune algorithms with verifiable & built-on lineage (meaning they can see a tamper-proof history of all changes in the past)
The sovereignty of both data (enabled by content-addressing/IPFS) and algorithm(e.g. Urbitenables peer-to-peer composability and portability of data & algorithm)
Accelerated innovation in LLM from the outpour of variants from the base open-source models
Reproducibility of training data output via Blockchain’s immutable record of past ETL operations & queries (e.g. Kamu)
One might argue that there’s a middle ground of Web2 open source platforms, but it’s still far from optimal for reasons discussed in this blog post by exaBITS.
Summary by AI: The closed-door nature of Big Tech’s LLM precludes the possibility of an “AI Democracy,” where every developer or user should be able to contribute both algorithms and data to an LLM model, and in turn receive a fraction of the future profits from the model. AI should be accessible for, relevant to, and owned by everyone. Blockchain networks will enable users to provide feedback, contribute data for potential profits from model monetization, and enable developers to have visibility and the ability to compose and fine-tune algorithms with verifiability and built-on lineage. The sovereignty of both data and algorithm will be enabled by web3 innovations such as content-addressing/IPFS and Urbit. Reproducibility of training data output via Blockchain’s immutable record of past ETL operations and queries will also be possible.
Installation of Incentives for Data Contribution
Problem
Today, the most valuable consumer data is proprietary to big tech platforms as an integral business moat. The tech giants have little incentive to ever share that data with outside parties.
What about getting such data directly from data originators/users? Why can’t we make data a public good by contributing our data and open-source it for talented data scientists to use?
Simply put, there’s no incentive or coordination mechanism for that. The tasks of maintaining data and performing ETL (extract, transform & load) incur significant overhead costs. In fact, data storage alone will become a $777 billion industry by 2030, not even counting computing costs. Why would someone take on the data plumbing work and costs for nothing in return?
Case in point, OpenAI started off as open-source and non-profit but struggled with monetization to cover its costs. Eventually, in 2019, it had to take the capital injection from Microsoft and close off its algorithm from the public. In 2024, OpenAI is expected to generate $1 billion in revenue.
Solution
Web3 introduces a new mechanism called dataDAO that facilitates the redistribution of revenue from the AI model owners to data contributors, creating an incentive layer for crowd-sourced data contribution. Due to length constraints, I won’t elaborate further, but below are two related pieces.
In conclusion, DePIN is an exciting new category that offers an alternative fuel in hardware to power today’s renaissance of innovations in web3 and AI. Although big tech companies have dominated the AI industry, there is potential for emerging players to compete by leveraging blockchain technologies: DePIN networks lower the barrier to entry in compute costs; blockchain’s verifiable & decentralized properties make true open IA possible; innovative mechanisms, such as dataDAOs, incentivize data contribution; and the immutable and tamper-proof property of Blockchain provides proof of creatorship to address concerns regarding the negative societal impact of AI.
There is an overwhelming amount of work going on in the Filecoin ecosystem, and it can be difficult to see how all the pieces fit together. In this blog post, I’m going to explain the structure of Filecoin and various components of the roadmap to hopefully simplify navigating the ecosystem. This blog is organized into the following sections:
What is Filecoin?
Diving into the Major Components
Final Thoughts
This post is intended to be a primer on the major goings-on in Filecoin land; it is by no means exhaustive of everything happening! Hopefully, this post serves as a useful anchor and the embedded links are jumping-off points for the intrepid reader.
What is Filecoin?
My short answer: Filecoin is enabling open servicesfor data, built on top of the IPFS protocol.
IPFS allows data to be uncoupled from specific servers —reducing the siloing of data to specific machines. In IPFS land, the goal is to allow permanent references to data — and do things like compute, storage, and transfer — without relying on specific devices, cloud providers, or storage networks. Why content addressing is super powerful and what CIDs unlock is a separate topic — worthy of its own blog post — that I won’t get into here.
Filecoin is an incentivized network on top of IPFS — in that it allows you to contract out services around data on an open market.
Today, Filecoin focuses primarily on storage as an open service— but the vision includes the infrastructure to store, distribute, and transform data. Looking at Filecoin through this lens, the path the project is pursuing and the bets/tradeoffs that are being taken become clearer.
It’s easier to bucket Filecoin into a few major components:
There are 3 core pillars of Filecoin, enabled by 2 critical protocol upgrades
Storage Market(s): Exists today (cold storage), improvements in progress.
Retrieval Market(s): In progress
Compute over Data (Off-chain Compute): In progress
FVM (Programmable Applications): In progress
Interplanetary Consensus (Scaling): In progress
Diving into the Major Components
Storage Market(s)
Storage is the bread and butter of the Filecoin economy. Filecoin’s storage network is an open market of storage providers — all offering capacity on which storage clients can bid. To date, there are 4000+ storage providers around the world offering 17EiB (and growing) of storage capacity.
Filecoin is unique in that it uses two types of proofs (both related to storage space and data) for its consensus: Proof-of-replication (PoRep) and Proof-of-Spacetime (PoST).
PoRep allows a miner to prove both that they’ve allocated some amount of storage space AND that there is a unique encoding of some data (could be empty space, could be a user’s data) into that storage space. This proves that a specific replica of data is being stored on the network.
PoST allows a miner to prove to the network that data from sets of storage space are indeed still intact (the entire network is checked every 24 hrs). This proves that said data is being stored (space) over time.
These proofs are tied to economic incentives to reward miners who reliably store data (block rewards) and severely penalize those who lose data (slashing). One can think of these incentives like a cryptographically enforced service-level agreement, except rather than relying on the reputation of a service provider — we use cryptography and protocols to ensure proper operation.
In summary, the Filecoin blockchain is a verifiable ledger of attestations about what is happening to data and storage space on the network.
A few features of the architecture that make this unique:
The Filecoin Storage Network (total storage capacity) is 17EiB of data — yet the Filecoin blockchain is still verifiable on commodity hardware at home. This gives the Filecoin blockchain properties similar to that of an Ethereum or a Bitcoin, but with the ability to manage internet-scale capacity for the services anchoring into the blockchain.
This ability is uniquely enabled by the fact that Filecoin uses SNARKs for its proofs — rather than storing data on-chain. In the same way zk-rollups can use proofs to assert the validity of some batched transactions, Filecoin’s proofs can be used to verify the integrity of data off-chain.
Filecoin is able to repurpose the “work” that storage providers would normally do to secure our chain via consensus to also store data. As a result, storage users on the network are subsidized by block rewards and other fees (e.g. transaction fees for sending messages) on the network. The net result is Filecoin’s storage price is super cheap (best represented in scientific notation per TiB/year).
Filecoin gets regular “checks” via our proofs about data integrity on the network (the entire network is checked 24 hrs!). These verifiable statements are important primitives that can lead to unique applications and programs being built on Filecoin itself.
While this architecture has many advantages (scalability! verifiability!), it comes at the cost of additional complexity — the storage providing process is more involved and writing data into the network can take time. This complexity makes Filecoin (as it is today) best suited for cold storage. Many folks using Filecoin today are likely doing so through a developer on-ramp (Estuary.tech, NFT.Storage, Web3.Storage, Chainsafe’s SDKs, Textile’s Bidbot, etc) which couples hot caching in IPFS with cold archival in Filecoin. For those using just Filecoin alone, they’re typically storing large scale archives.
However, as improvements land both to the storage providing process and the proofs, expect more hot storage use cases to be enabled. Some major advancements to keep an eye on:
✅ SnapDeals — coupled with the below, storage providers can turn the mining process into a pipeline, injecting data into existing capacity on the network to dramatically lessen time to data landing on-chain.
🔄 Sealing-as-a-service / SNARKs-as-a-service — allowing storage providers to focus on data storage and outsource expensive computations to a market of specialized providers.
🔄 Proofs optimizations — tuning hardware to optimize for the generation of Filecoin proofs.
🔄 More efficient cryptographic primitives — reducing the footprint or complexity of proof generation.
Note: All of this is separate from the “read” flow — which techniques for faster reads exist today via unsealed copies. However, for Filecoin to get to web2 latency we will need Retrieval Market(s), discussed in the next section.
Retrieval Market(s)
The thesis with retrieval markets is straightforward: at scale, caching data at the edge via an open market can solve for the speed of light problem and result in performant delivery at lower costs than traditional infrastructure.
Why might this be the case? The argument is as follows:
The magic of content addressing (using fingerprints of content as the canonical reference) means data is verifiable.
This maps neatly to building a permissionless CDN — meaning anyone can supply infrastructure and serve content — as end users can always verify that the content they receive back is the content they requested (even from an untrusted computer).
If anyone can supply infrastructure into this permissionless network, a CDN can be created from a market of edge-caching nodes (rather than centrally planning where to put these nodes) and use incentive mechanisms to bootstrap hardware — leading to the optimal tradeoff on performance and cost.
The way retrieval markets are being designed on Filecoin, the aim is not to mandate a specific network to be used — rather to let an ecosystem evolve (e.g. Magmo, Ken Labs, Myel, Filecoin Saturn, and more) to solve the components involved with building a retrieval market.
This video is a good primer on the structure and approach of the working group and one can follow progress here.
Note: Given latency requirements, retrievals happen off-chain, but the settlement for payment for the services can happen on-chain.
Compute over Data (Off-chain Compute)
Compute over data is the third piece of the open services puzzle. When one thinks of what needs to be done with data, it’s typically not just storage and retrieval — users also want to be able to transform the data. The goal with these compute over data protocols are generally to perform computation over IPLD.
For the unfamiliar, IPLD aims to be the data layer for content-addressed systems. It can be used to describe a filesystem (like UnixFS which IPFS uses), Ethereum data, Git data, — really anything that is hash linked. This video might be a helpful primer.
The neat thing about IPLD being generic is that it can be an interface for all sorts of data — and by building computation tools that interact with IPLD, we reduce the complexity for teams building these tools to have their networks be compatible with a wide range of underlying types of data.
Note: This should be exciting for any network building on top of IPFS / IPLD (e.g. Celestia, Gala Games, Audius, Ceramic, etc)
Of course, not all compute is created equal — and for different use cases, different types of compute will be needed. For some use cases, there might be stricter requirements for verifiability — and one may want a zk proof along with the result to know the output was correctly calculated. For others, one might want to keep the data entirely private — and so instead might require fully homomorphic encryption. For others, one may want to just run batch processing like on a traditional cloud (and rely on economic collateral or reputational guarantees for correctness).
There are a bunch of teams working on different types of compute — from large scale parallel compute (e.g. Bacalhau), to cryptographically verifiable compute (e.g. Lurk), to everything in between.
One interesting feature of Filecoin is that the storage providers have compute resources (GPUs, CPUs — as a function of needing to run the proofs) colocated with their data. Critically, this feature sets up the network well to allow compute jobs to be moved to data — rather than moving the data to external compute nodes. Given that data has gravity, this is a necessary step to set the network up to support use cases for compute over large datasets.
Filecoin is set up well to have compute layers be deployed on top as L2s.
One can follow the compute over data working group here.
FVM (Programmable Applications)
Up until this point, I’ve talked about three services (storage, retrieval, and compute) that are related to the datastored on the Filecoin network. These services and their composability can lead to compounding demand for the services of the network — all of which ultimately anchor into the Filecoin blockchain and generate demand for block space.
But how can these services be enhanced?
Enter the FVM — Filecoin’s Virtual Machine.
The FVM will enable computation over Filecoin’s state. This service is critical — as it gives the network all the powers of smart contracts from other networks — but with the unique ability to interact with and trigger the open services mentioned above.
With the FVM, one can build bespoke incentive systems to make more sophisticated offerings on the network:
Undercollateralized lending markets for storage providers
ETL pipelines
… and so much more
Filecoin’s virtual machine is a WebAssembly (WASM) VM designed like a hypervisor. The vision with the FVM is to support many foreign runtimes, starting with the Ethereum Virtual Machine (EVM). This interoperability means Filecoin will support multiple VMs — on the same network contracts designed for the EVM, MoveVM, and more can be deployed.
By allowing for many VMs, Filecoin developers can deploy hardened contracts from other ecosystems to build up the on-chain infrastructure in the Filecoin economy, while also making it easier for other ecosystems to natively bridge into the services on the Filecoin network. Multiple VM support also allows for more native interactions between the Filecoin economy and other L1 economies.
Note the ipld-wasm module — the generalized version of this will be the IPVM work (which could be backported here). Source: https://fvm.filecoin.io
The FVM is critical as it provides the expressiveness for people to deploy and trigger custom data services from the Filecoin network (storage, retrieval, and compute). This feature allows for more sophisticated offerings to be built on Filecoin’s base primitives, and expand the surface area for broader adoption.
Note: For a flavor of what might be possible, this tweet thread might help elucidate how one might use smart contracts and the base primitives of Filecoin to build more sophisticated offerings.
Most importantly, the FVM also sets the stage for the last major pillar to be covered in this post: interplanetary consensus.
One can follow progress on the FVM here, and find more details on the FVM here.
Interplanetary Consensus (Scaling)
Before diving into what interplanetary consensus is, it’s worth restating what Filecoin is aiming to build: open services for data (storage, retrieval, compute) as credible alternatives to the centralized cloud.
To do this, the Filecoin network needs to operate at a scale orders of magnitude above what blockchains are currently delivering:
Product requirements for the Filecoin network.
Looking at the above requirements, it may seem contradictory for one chain to target all of these properties. And it is! Rather than trying to force all these properties at the base layer, Filecoin is aiming to deliver these properties across the network.
With interplanetary consensus, the network allows for recursive subnets to be created on the fly. This framework allows each subnet to tune its own trade off between security and scalability (and recursively spin up subnets of its own) — while still checkpointing information to their respective parent subnets.
This setup means that while Filecoin’s base layer can be highly secure (allowing many folks to verify at home on commodity hardware) — Filecoin can have subnets that are natively connected that can make different trade offs, allowing for more use cases to be unlocked.
A few interesting properties based on how interplanetary consensus is being designed:
Each subnet can spin up their own subnets (enabling recursive subnets)
Native messaging up, down, and across the tree — meaning any of these subnets can communicate with each other
Tunable tradeoffs between security and scalability (each subnet can choose their own consensus model and can choose to maintain their own state tree).
Firewall-esque security guarantees from children to parents (think of each subnet as being like a limited liability chain up to the tokens injected from the perspective of the parent chain).
To double click on some of the things interplanetary consensus sets Filecoin up for:
Because subnets can have different consensus mechanisms, interplanetary consensus opens the door for subnets that allow for native communication with other ecosystems (e.g. a Tendermint subnet for Cosmos).
Enabling subnets to tune between scalability and security (and enabling communications to subnets that make different trade offs) means Filecoin can have different regions of the network with different properties. Performant subnets can get hyper fast local consensus (to enable things like chat apps) — while allowing for results to checkpoint into the highly secure (and verifiable and slow) Filecoin base layer.
In a very high throughput subnet (a single data center, running a few nodes) — the FVM/IPVM work could be used to simply task schedule and execute computation directly “on-chain” — with native messaging and payment bubbling back up to more secure base layers.
Learn more by reading this blogpost and following the progress of ConsensusLab. This Github discussion may also be useful to contextualize IPC vs L2s.
Final Thoughts
So, after reading all the above, hopefully clearer what Filecoin is — and how it’s not exactly like any other protocol out there. Filecoin’s ambition is not just to be a storage network (as Tesla’s ambition was not to just ship the Roadster) — the goal is to facilitate a fully decentralized web powered by open services.
Compared to most other web3 infra plays, Filecoin is aiming to be substantially more than a single service. Compared to most L1s, Filecoin is targeting a set of use cases that are uniquely enabled through the architecture of the network. Excitingly, this means rather than competing for the same use cases, Filecoin can uniquely expand the pie for what can actually be done on crypto rails.
Disclaimer: Personal views, not reflective of my employer nor should be treated as “official”. This is my distillation of what Filecoin is and what makes it different based on my time in the ecosystem. Thanks to @duckie_han and @yoitsyoung for helping shape this.